カーネル法
| 機械学習および データマイニング |
|---|
 |
|
| 構造化予測(英語版) |
| 学会・論文誌等
|
|
|
|
カーネル法(カーネルほう、英: kernel method)はパターン認識において使われる手法の一つで、 判別などのアルゴリズムに組み合わせて利用するものである。よく知られているのは、サポートベクターマシンと組み合わせて利用する方法である。
パターン認識の目的は、一般に、 データの構造(例えばクラスタ、ランキング、主成分、相関、分類)を見つけだし、研究することにある。この目的を達成するために、 カーネル法ではデータを高次元の特徴空間上へ写像する。特徴空間の各座標はデータ要素の一つの特徴に対応し、特徴空間への写像(特徴写像)によりデータの集合はユークリッド空間中の点の集合に変換される。特徴空間におけるデータの構造の分析に際しては、様々な方法がカーネル法と組み合わせて用いられる。特徴写像としては多様な写像を使うことができ(一般に非線形写像が使われる)、それに対応してデータの多様な構造を見いだすことができる。
カーネル関数
カーネル法の名前はカーネル関数を使うことに由来する[1][2]。カーネル関数は、特徴空間中のデータの座標の明示的な計算を経由せずに、特徴空間における内積をデータから直接計算する手段を与える。内積を評価するためにカーネル関数を使うと、明示的な座標の計算を経るよりもしばしば計算量が少なくて済む。
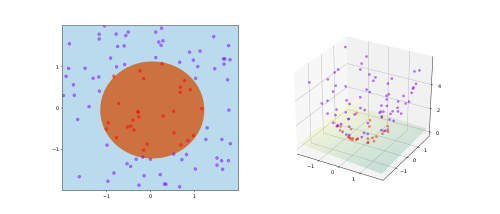

カーネル関数を使って、計算複雑度の増大を抑えつつ内積にもとづく解析手法を高次元特徴空間へ拡張するアプローチを、一般にカーネルトリックと呼ぶ。カーネル関数はベクトルのみならず、系列データ、テキスト、画像、グラフなどに対しても導入されている。
組み合わせ
カーネル法と組み合わせて使うことのできるアルゴリズムには、サポートベクターマシン (SVM)、Fisher の線形判別分析(英語版) (LDA)、主成分分析 (PCA)、正準相関分析(英語版)、リッジ回帰、スペクトルクラスタリング(英語版)などの多くの手法がある。
1990年代半ばからこの手法を精力的に開発してきた研究コミュニティの文化を反映して、多くのカーネル法のアルゴリズムは凸最適化あるいは固有値問題に基づいており、 計算効率が良く、統計学的な基礎づけを伴っている。これらのアルゴリズムの統計的性質は、典型的には統計的学習理論(英語版)を用いて解析される。
応用
現在のところ、主要な応用分野は地球統計学、クリギング、逆距離加重法(英語版)、バイオインフォマティクス、テキスト分類、手書き文字認識などである。カーネル関数とカーネルアルゴリズムとの組み合わせは任意であるため、意外性のある応用が可能である。例えば、生物系列上の回帰問題や、文書の分類、画像のクラスタリングなどである。
参考文献
 | この項目は、ソフトウェアに関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(PJ:コンピュータ/P:コンピュータ)。 |
- 表示
- 編集











